
배열이란?
배열은 연속적인(인접한) 메모리 공간에 저장된, 같은 타입의 데이터들의 모임이다. 가장 기초적인 자료구조.

배열의 연산들
- 접근 연산 : 항상 O(1)
- 배열의 접근 연산은 index를 이용하고 이는 random access로, 빠른 속도를 보여준다.
- 탐색 연산(선형 탐색이라고 가정할 때 배열의 길이에 비례한다. O(n) )
# 선형 탐색
def lenear_search(arr, n, key):
for i in range(n):
# found
if (arr[i] == key):
return i
# If the key is not found
return -1- 삽입 연산 : 맨 끝자리에 대한 삽입은 해당 자리를 찾아서 넣기만 하면 끝이다. 즉 접근 연산과 할당 연산 두개이기 때문에 O(1) 이다. 그러나 나머지 자리에 대한 삽입은 먼저 그 뒤의 원소들을 한칸씩 뒤로 옮긴(shift) 후에 원소를 넣는다. 이런 이동 과정 때문에 O(n) 시간이 걸린다.
- 이렇듯 위치에 따라 다르지만, 평균적으로 O(n) 시간이 걸린다.
- 삭제 연산 : 시간복잡도는 삽입 연산과 비슷하다. 맨 마지막 자리의 원소를 삭제할 때엔 O(1)이지만, 나머지 자리들은 없앤 후에 그 뒤의 원소들을 앞으로 옮겨야 한다(shift). 이 이동 과정 때문에 O(n) 시간이 걸린다.
파이썬과 같은 현대적인 언어들은 기본 지원되는 메소드를 통해 자리에 상관 없이 삽입, 삭제를 편하게 구현을 할 수 있다.
arr= [1,2,3]
# 파이썬의 기본 배열 메소드들
arr.insert(0,10) # [10,1,2,3]
arr.remove(3) # [10,1,2]그래도 여전히 시간 복잡도는 그대로다.
정적 배열의 문제점
정적 배열의 큰 문제 중 하나는 처음에 배열을 선언할 때 배열의 크기를 지정해야 하며, 그 이상의 데이터를 집어넣을 수 없다는 점이다. 즉 원소의 개수가 제한된다.
// c++의 정적 배열
int arr[3];
arr[0]=100;
arr[1]=100;
arr[2]=100;
arr[3]=100; // error!동적 배열
배열의 문제점을 해결하기 위해 고안된 것이 자료의 개수가 변함에 따라 크기가 변경되는 동적 배열(dynamic array)이다.
동적 배열은 언어 차원에서 지원되는 기능이 아니라, 배열을 이용해 만들어 낸 별도의 자료구조다. (c++의 vector. python은 기본적으로 list 를 동적 배열로써 지원)
내부적으로 배열을 이용하기 때문에, 동적 배열은 배열이 갖는 다음 특성들을 그대로 이어받는다.
- 원소들은 메모리의 연속된 위치에 저장됨
- 특정 위치의 원소를 접근, 변경하는 연산을 O(1)에 할 수 있다.
추가적인 특성
- 배열의 크기를 변경하는 resize() 연산이 가능. O(n)
- 주어진 원소를 배열의 맨 끝에 추가함으로써 크기를 1 늘리는 append() 연산을 지원한다. O(1)
동적 배열은 크기가 바뀌어야 할 때 새 배열을 ‘동적으로 할당’받은 뒤 기존 원소들을 복사하고, 변수가 새 배열을 참조하도록 바꿔치기한다. 따라서 동적 배열 클래스는 현재 배열의 크기와 포인터를 저장하고 있을 것이다.
class 동적배열 {
int size; // 배열의 현재 크기
element * array // 배열을 가리키는 포인터
// ...
}append() 가 O(1) 인 이유는, 처음에 메모리를 할당받을 때 배열의 크기가 커질 때를 대비해 여유분의 메모리를 미리 할당받아두기 때문이다. 즉, 실제로는 용량이 더 있으면서 배열의 크기(size)는 현재 가진 원소의 개수만큼만 인식하게 된다.
연결 리스트(linked list)
정적이든 동적이든, 결국 배열의 단점은 삽입과 삭제시의 이동 과정이다.
연결 리스트는 이 문제를 해결하기 위해 고안된 자료구조로, 특정 위치에서의 삽입과 삭제를 O(1)에 할 수 있게 해준다.
배열이 연속된 메모리 공간에 원소들을 저장하던 것과 달리, 연결 리스트는 원소들이 (일반적인 변수와 같이) 메모리 여기저기 흩어져있고 각 원소들이 이전과 다음 원소를 가리키는 포인터를 갖는다. 그리고 원소와 포인터의 한 묶음을 노드라고 부른다.
링크드 리스트는 보통 첫번째 노드와 마지막 노드에 대한 포인터를 갖고 있는데, 이를 각각 head와 tail이라고 부른다. (head를 중요하게 보고, tail은 선택사항이다.)
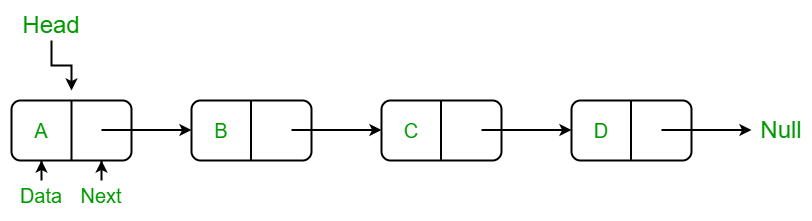
// 일방향 링크드 리스트의 노드
struct node{
int data; // 데이터
struct node * next; // 다음 노드를 가리킬 포인터. 자기 참조
}장점
삽입, 삭제시의 과정이 아주 간단하다. 이전,이후 노드의 포인터를 바꾸면 된다. (맨 처음, 맨 끝 노드에 대한 과정은 또 달라서 실제로 구현할 땐 보이는것보다 어렵긴 하다)
추가하고 싶은 위치의 노드 주소값을 알고 있다면 O(1) 에 가능하다. 그게 아니라 배열처럼 index로 찾아가려면 이동하는 만큼, 즉 O(n) 이 걸린다.
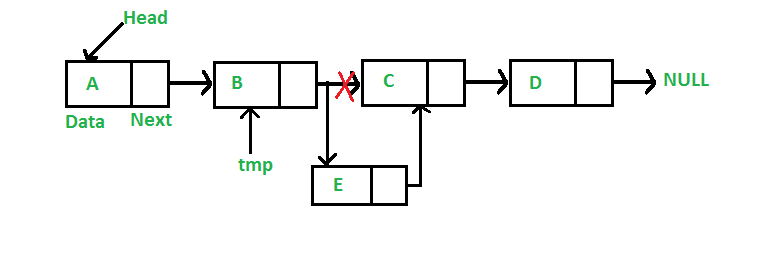

단점
배열과는 달리 메모리에 연속적으로 저장되어있지 않기 때문에, 특정 위치의 값을 찾기가 쉽지 않다. i번째 노드를 찾아가려면 결국 첫번째 노드에서부터 하나씩 포인터를 따라가며 나올 때까지 찾는다. 이는 O(n) 시간이다.
또한 따로 포인터를 저장해야 하기 때문에 원소의 개수만큼 포인터를 위한 메모리(overhead)가 필요하다. 길이를 n이라고 할 때 32bit 컴퓨터라면 4 * n 바이트, 64bit 컴퓨터라면 8 * n 바이트가 필요하게 되는 식이다.
배열 vs 링크드 리스트
| 배열 | 링크드 리스트 | |
|---|---|---|
| 메모리상의 배치 | 연속 | 불연속 |
| 임의 위치의 원소 접근 | O(1) | O(n) |
| 임의 위치에 원소 추가,삭제 | O(n) | O(1) |
| 추가적으로 필요한 공간(overhead) | O(n) |
정리해보자. 임의 위치 원소에 대해 삽입이나 삭제를 할 일이 없거나, 하더라도 맨 끝에서만 이루어질 경우엔 배열이 항상 더 좋은 선택이다. 그리고 프로그램 특성상 크기가 변할 일이 없고 메모리가 중요하다면 정적배열이 좋다. 그게 아니라면 언제나 동적 배열이 안정적이라고 생각한다.
만약 임의의 원소를 접근하는게 아니라, 임의의 위치에 삽입과 삭제를 할 일이 많다면 연결리스트가 좋은 선택이다. 가령 브라우저의 히스토리 이동 기능, 음악 플레이어 등을 링크드리스트로 구현할 수 있다. 앞으로 가기, 뒤로 가기, 그리고 현재의 주소만 필요하다면, 링크드리스트만으로 충분하다.
연결리스트의 종류
단일 연결리스트(singly linked list)는 위에서 살펴봤듯이 헤드 포인터가 가장 앞의 노드를 가리키고, 각 노드는 데이터와 링크(포인터) 필드를 1개 담고 있어 노드끼리 한 방향으로 포인팅하며 이어져있는 형태다.
반면 이중 연결리스트(doubly linked list)는 노드가 링크 필드를 2개 담고 있어서 앞뒤의 노드들끼리 서로 포인팅하는 형태. 양방향으로 이동해야할 경우에 유용하고, 중간에서 출발하더라도 모든 노드를 방문할 수 있다.
원형 연결리스트(circular linked list)는 마지막 노드가 첫번째 노드를 포인팅해서, 중간에서 출발하더라도 맨 첫번째를 포함해 모든 노드를 방문할 수 있다.
이중 원형 연결리스트도 있다.
끝
후기
배열과 연결리스트는 그 자체로도 의의가 있지만, 응용해서 다른 자료구조들을 구성할 때 엄청 자주 쓰여서 더 중요하다고 생각한다. stack, queue, tree, graph… 등등 거의 모든 자료구조들에 응용된다고 보면 될 것 같다.
링크드 리스트는 구현의 복잡함 때문에 왠만하면 잘 안 쓴다. 알고리즘을 풀면서도 쓴 적이 10번 미만.. 그래도 언젠가 필요하게 되면 쫄지 않고 쓰는 멋진 개발자가 되고 싶다.
더 배울 부분들
- 배열과 Cache hit rate
- 동적 배열과 overhead
- 포인터의 메모리 크기는 왜 32, 64비트 컴퓨터마다 다를까
참조
알고리즘 문제해결전략 - 구종만
https://www.geeksforgeeks.org/array-data-structure/?ref=lbp
https://www.geeksforgeeks.org/search-insert-and-delete-in-an-unsorted-array/
https://www.youtube.com/watch?v=C6MX5u7r72E&list=PLtqbFd2VIQv4O6D6l9HcD732hdrnYb6CY&index=5
'CS > 자료구조 & 알고리즘' 카테고리의 다른 글
| B-tree와 B+tree (0) | 2023.03.03 |
|---|---|
| 대표적인 선형 자료구조(스택, 큐, 덱) (0) | 2023.02.08 |
| 알고리즘 시간 복잡도 분석 (0) | 2023.01.03 |
| 문제 해결 알고리즘! (0) | 2022.12.21 |
| 추상 자료형과 알고리즘, 의사 코드 (0) | 2022.11.26 |