알고리즘을 평가하는 두 가지 주요 기준은 시간과 공간이다. 이 두 요소는 서로 상충하는 경우가 많다. 메모리를 아끼려면 속도를 희생하고, 속도를 높이려면 메모리를 희생하는 식. 통상 더 중요시되는 기준은 시간이다. 프로그래밍 대회를 나가거나 알고리즘을 발명할게 아니라면 대부분 코딩 테스트를 보는 입장에서, 시간 제한을 지키는 것이 문제를 해결하는 것 다음으로 중요한 태스크다.
시간 복잡도란?
시간 복잡도(time complexity)란 가장 널리 사용되는 알고리즘의 수행 시간 기준으로, 알고리즘이 실행되는 동안 수행하는 기본적인 연산의 수를 입력의 크기에 대한 함수로 표현한 것입니다.
알고리즘의 속도를 비교하는 가장 직관적인 방법은 실제 실행시간 측정이다. 그러나, 이는 알고리즘의 속도를 일반적으로 논하는 기준이 되기는 어렵다. 프로그램의 수행 시간은 사용된 언어, 하드웨어, 운영체제 등 수많은 외부적 요소에 의해 바뀔 수 있기 때문이다. m1 맥북과 매킨토시 컴퓨터의 실행시간은 다를 수 밖에 없다.
그리고 프로그램의 실행 시간은 다양한 입력값, 상황에 대한 실행 시간을 반영하지 못한다. 입력의 크기나 특성에 따라, 어떤 라이브러리를 썼느냐에 따라 수행 시간이 달라지기 때문이다.
즉, 알고리즘 수행 시간의 기준은 보편성을 가져야 한다. 그래서 이제부터 이론적인 이야기가 나오게 된다.
반복문이 지배한다(dominate)
한 가지 항목이 전체의 대소를 좌지우지하는 것을 지배한다고 표현합니다.
알고리즘의 수행 시간을 지배하는 것은 무엇일까? 바로 반복문이다. 대부분의 알고리즘은 입력의 크기에 따라 반복문의 수행 횟수가 정해진다. 짧은 거리를 달릴 때는 자전거가 빠를 수 있는 것처럼, 입력의 크기가 작을 때는 반복 외의 다른 부분들이 갖는 비중이 클 수 있지만, 입력의 크기가 커지면 커질수록 반복문이 알고리즘의 수행 시간을 지배하게 된다.
Big-O Notation
정확한 시간 복잡도는 계산하기 너무 힘들다. T(...) 식으로 정확하게 나타낼 수는 있는데, 모든 명령어를 고려하기에도 피곤하고 실질적으로는 가장 빠르게 증가하는 항이 가장 중요하기 때문이다. 거기에다 상수는 제외하고 딱 최고차항만을 표기하는게 빅 O 표기법이다.
예를 들어 어떤 알고리즘의 수행시간이 f(N) = 3N^2 + 10N + 1 일 때, 가장 빠르게 증가하는 항 3N^2의 상수를 뺀 N^2이 빅오 표기법에서 표기되는 식이다.
알고리즘의 수행 시간은 크게 몇가지로 분류된다.
상수 시간 알고리즘
상수(constant) 시간 알고리즘이란, 입력 데이터의 크기에 상관없이 언제나 고정된 시간이 걸리는 알고리즘이다. 데이터가 얼마나 증가하든 성능에 영향을 거의 미치지 않는다.
예를 들어 배열에서 index를 이용해 원소에 접근하는 연산이 있다. index를 통해 해당 주솟값을 바로 찾아가는 random access이기 때문에 이는 O(1)이다.
arr = [1,2,3]
print(arr[0]) # index 접근 연산
arr.append(10)
arr.pop()즉 기본적인 연산이다.
선형 시간 알고리즘
선형 시간(linear time) 알고리즘은 입력의 크기에 대비해 걸리는 시간을 그래프로 그렸을 때 정확히 직선이 되는 알고리즘을 말한다. 대개 우리가 찾을 수 있는 알고리즘 중 가장 좋은 알고리즘인 경우가 많다. 주어진 입력 N개를 최소한 한 번씩 쳐다보기라도 하려면 최소한 N번이 필요하니까.
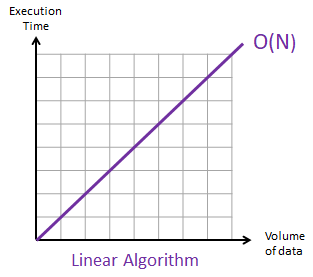
# 선형 탐색 (일일이 다 확인하기)
def linearSearch(my_list, target):
for element in my_list:
if element == target:
return True
return False보통 반복문이 딱 하나이고 배열 전체의 원소에 대한 연산(접근, 더하기 등)을 할 때 선형 시간을 필요로 한다. 위 파이썬 코드에선 리스트의 길이가 입력 N이고 저 함수의 실행 시간은 N(에 정비례)이라고 할 수 있다.
선형 이하 시간(sub-linear time) 알고리즘
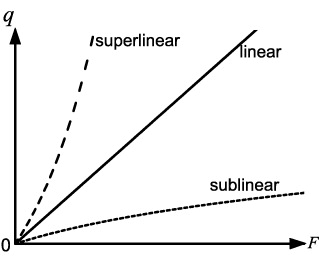
대부분의 경우 로그 시간 알고리즘이지만, 꼭 log만이 아니라 선형 시간 복잡도보다 상승률이 낮은 알고리즘이면 모두 선형 이하 시간 알고리즘이라고 부른다.
이미 정렬된 배열이라는 전제 하에, 찾으려는 수를 배열을 반씩 쪼개서 찾는 탐색 방법인 binary search 는 log2 N 의 시간 복잡도를 갖는다. 예를 들어 길이 16의 배열에서 하나의 원소를 찾을 때 4번 실행된다.
# 이진 탐색 : O(logN)
def binary_search(arr, x):
low = 0
mid = 0
high = len(arr) - 1
while low <= high:
# 중간 index
mid = (high + low) // 2
# If x is greater, ignore left half
if arr[mid] < x:
low = mid + 1
# If x is smaller, ignore right half
elif arr[mid] > x:
high = mid - 1
# x is present at mid
else:
return mid
# element not present
return -1
지수 시간 알고리즘
다항 시간 알고리즘
N, N^2, 그 외 N의 거듭제곱들의 선형 결합으로 이뤄진 식들을 다항식이라고 부릅니다. 반복문의 수행 횟수를 입력 크기의 다항식으로 표현할 수 있는 알고리즘들을 다항 시간 알고리즘이라고 부릅니다.
다항 시간이라는 하나의 분류에 포함되는 알고리즘 간에는 엄청나게 큰 시간 차이가 날 수 있습니다. 그리고 다항 시간보다 더더욱 오래 걸리는 알고리즘들이 있습니다.
지수 시간(exponential time) 알고리즘
재귀 피보나치의 경우, n이 1 증가할 때마다 실행시간은 약 2배 증가한다. 즉 2^n 시간 복잡도를 갖는다. 입력이 증가할수록 다른 알고리즘들보다 기하급수적으로 빨라진다.
피보나치가 왜 2^n 복잡도를 갖는지 생각해보자. 첫 실행 때, n이 1보다 큰 이상 두 번의 재귀호출을 하게 된다. 그리고 당연히 호출된 함수들도 또 다시(n이 1보다 큰 이상) 2번의 재귀호출을 한다. 이렇게 분열증식하는 세포처럼 2배씩 증가하게 된다. 그렇게 재귀호출은 n이 1보다 작거나 같을 때 끝나게 된다.
# 재귀 피보나치
def fib(n):
if n <= 1:
return n
else:
return(fib(n-1) + fib(n-2))정확히는 O(1.618)^n 이라고 한다. 1.618은 황금비. (https://www.geeksforgeeks.org/time-complexity-recursive-fibonacci-program/)
지수 시간 알고리즘은 Brute Force 등에서도 볼 수 있다.
지수 시간 알고리즘은 수학의 조합의 연장선이라고 할 수 있다. 가능한 모든 조합으로 남의 비밀번호 뚫기 (가능한 키의 개수 ^ n), 어떤 요리를 만드는 경우의 수 등등.
아직 많은 문제들은 지수 시간보다 빠른 알고리즘을 찾지 못한 문제들이 아주 많기 때문에, 다항 시간과 지수 시간 사이의 경계는 효율적인 해결법을 찾아낸 문제와 아직 찾아내지 못한 문제의 경계 역할을 하고 있습니다.
시간복잡도 총정리
// 1. O(log(n))
while(n)
n/=2;
// 2.
for(int i=0;i*i<=n;i++);
// 3.
for(int i=0;i<n;i++);
// 4.
for(int i=0;i<n;i++)
for(int j=i;j;j/=2);
// 5.
for(int i=0;i<n;i++)
for(int j=0;j*j<=i;j++);
// 6.
for(int i=0;i<n;i++)
for(int j=0;j<n;j++);
// 7.
for(int i=0;i<n;i++)
for(int j=0;j<n;j++)
for(int k=0;k<n;k++);
// 8.
int function(int n){
if(n==0||n==1)
return 1;
return function(n-1)+function(n-2);
}
// 9.
// n개의 데이터를 나열하는 방법의 수
void function(int x, vector<int> pick, vector<bool> picked){
if(x==n){
for(int i=0;i<pick.size();i++)
printf("%d\n", pick[i]);
return;
}
for(int i=0;i<n;i++){
if(picked[i])
continue;
pick.push_back(i);
picked[i]=true;
function(x+1, pick, picked);
pick.pop_back();
picked[i]=false;
}
return;
}
정답
- O(log(n))
- O(sqrt(n))
- O(n)
- O(nlog(n))
- O(nsqrt(n))
- O(n^2)
- O(n^3)
- O(2^n)
- O(n!)
수행 시간 어림짐작하기
많은 프로그래밍 대회 참가자들이 사용하는 주먹구구 법칙은 다음과 같습니다.
입력의 크기를 시간 복잡도에 대입해서 얻은 반복문 수행 횟수에 대해, 1초당 반복문 수행 횟수가 1억(10^8)을 넘어가면 시간 제한을 초과할 가능성이 있다.
예를 들어, N=10000일 때 O(N^2) 알고리즘을 쓰게 되면 반복문이 1억 실행되므로 이론적으로는 맞다. 그러나 알고리즘마다 추가적인 연산들이 있으니까 문제 풀이에 있어 위험하다고 할 수 있다. 어디까지나 주먹구구이고, 프로그램을 직접 보기 전에는 단정할 수 없다. 그래서 언제나 충분한 여유를 두는 것이 중요하다.
각 복잡도의 알고리즘이 1초 안에 풀 수 있는 입력의 크기는…
O(N^3) : 2,560
O(N^2) : 40,960
O(N log N) : 20,000,000
O(N) : 160,000,000
바킹독님의 강의를 보면서 시간제한에 대한 노하우를 추가적으로 배우고 있다. 이 분은 N의 크기를 더 보수적으로 상정하신다.
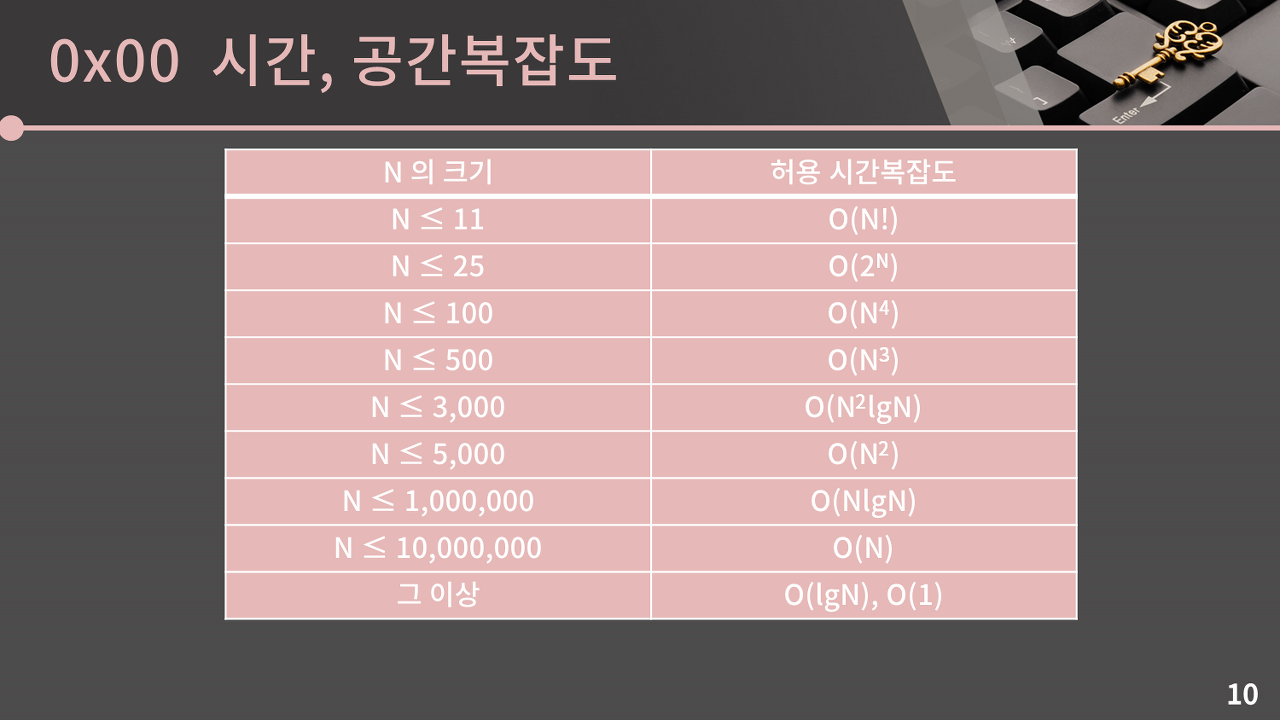
출처 : https://blog.encrypted.gg/922
백준에서 제시하는 시간제한은 대부분 1초 단위다. 그리고 입력값 N의 갯수를 생각하면 된다.
아래는 단순한 정렬을 물어보는 문제. N의 크기는 최대 1,000,000이고, 시간제한은 2초. 컴퓨터가 1초에 1억개의 연산을 할 수 있다고 가정할 때, 2억개의 연산을 할 수 있다. 즉 O(N^2) 알고리즘으로는 풀 수 없다. 이 문제는 O(N log N) 이하의 알고리즘으로 풀어야 한다.

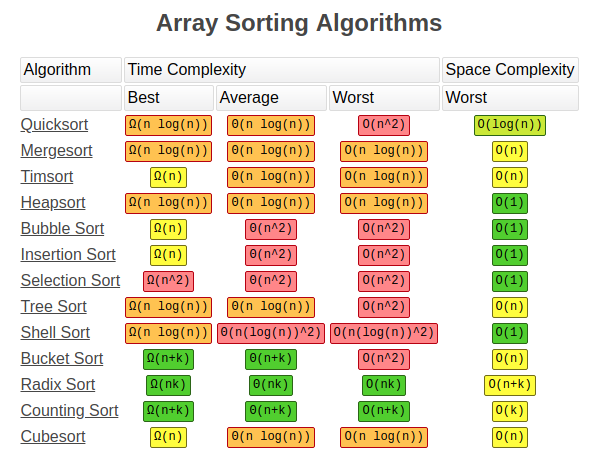
정렬 알고리즘들의 시간 복잡도. 중요한건 worst case를 고려해야 한다는 것. 위의 문제는 merge sort, heap sort, counting sort(값의 범위가 공간복잡도를 만족하는 경우에만), time sort(?) 등으로 풀어야 한다.

참조:
알고리즘 문제 해결 전략 - 구종만
https://www.101computing.net/big-o-notation/
https://lamfo-unb.github.io/2019/04/21/Sorting-algorithms/
https://baactree.tistory.com/26
'CS > 자료구조 & 알고리즘' 카테고리의 다른 글
| B-tree와 B+tree (0) | 2023.03.03 |
|---|---|
| 대표적인 선형 자료구조(스택, 큐, 덱) (0) | 2023.02.08 |
| 배열과 연결리스트 (0) | 2023.01.15 |
| 문제 해결 알고리즘! (0) | 2022.12.21 |
| 추상 자료형과 알고리즘, 의사 코드 (0) | 2022.11.26 |