
💡 발단
프로젝트에서 맞닥뜨린 요구사항은 이렇다.
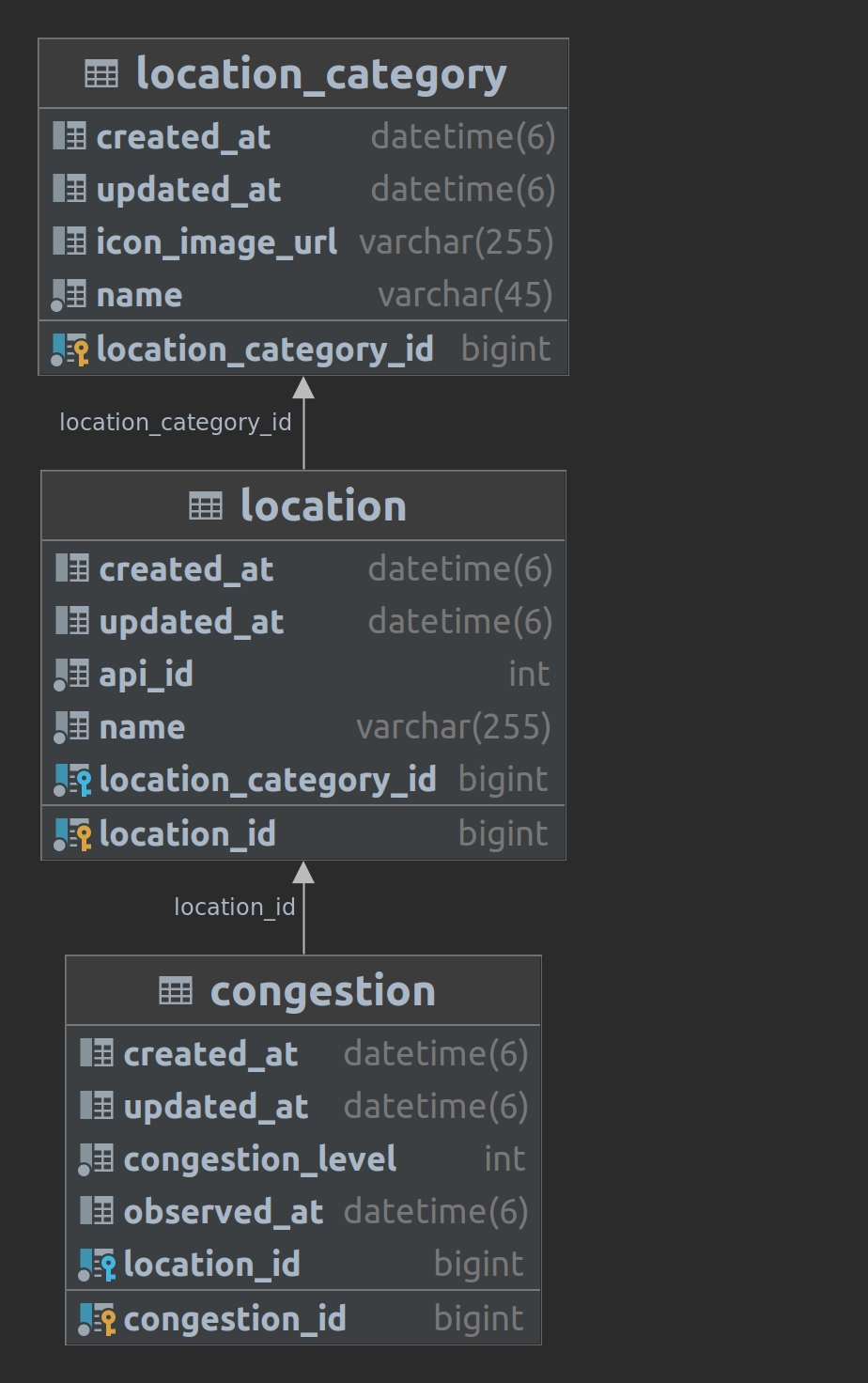
엔티티로는 로케이션이 있고, 각 로케이션에 대해서 서울시 인구 혼잡도 API로부터 5분마다 혼잡도 데이터를 적재한다.
ex. 홍대입구역(id=3)에 대한 9시의 인구혼잡도가 2레벨(기획상 1~3으로 나뉜다)이라면
congestion(location_id=3, congestion_level=2, observed_at=2023-08-05 18:35:43.769817) 으로 저장된다.
나는 각 location별로 가장 최근의 혼잡도 (congestion)을 조회해야 했다.
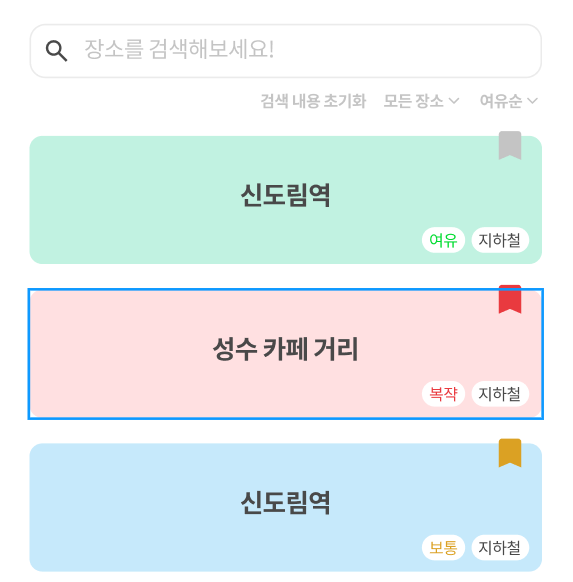
아래 사진은 와이어프레임인데, 각 카드 하단의 '여유', '복쟉', '보통'이 각 로케이션의 가장 최근 혼잡도 레벨이다.
'지하철'은 location_category에 해당.
💦 삽질 과정
쿼리를 간단하게 요약하면 "엔티티별로 가장 최근의 연관관계 레코드를 함께 조회"하는 것이다.
꽤 쿼리문이 복잡해서, 중간 삽질 과정은 QueryDSL이 아닌 SQL로 대부분 설명하겠다.
🙄 무식하게 다 가져오기
// Location 조회 -> -> 마지막 원소를 가져오기
List<Location> locations = queryFactory.selectFrom(location)
.where(inLocationCategoryId(categoryIds))
.fetch(); // IN categoryId
// 각 congestion List를 조회.
for (Location location : locations) {
// 여기서 매번 조회 쿼리가 발생
List<Congestion> congestionList = location.getCongestionList();
// 마지막 원소 (가장 최신 레코드) 가져오기
Congestion congestion2 = congestionList.get(congestionList.size() - 1);
}JPA 스럽지도 않고, 로케이션이 많아지면 많아질수록 쿼리 성능이 떨어지는 로직이다.
게다가 congestion 레코드가 하나도 없는 경우에는 Index 에러가 발생한다.
🙄 개수로 limit 걸기 : 누락, 중복 문제
location 개수별로 limit을 걸어서 congestion으로부터 가져오는 방법.
SQL 쿼리는 다음과 같다.
select count(*)
from location; # 9개
select location_id, congestion_level, observed_at
from congestion
order by observed_at DESC
limit 9;
⚠ 문제 : FK에 의존하지 않으니 누락, 중복 문제가 발생할 수 있다.
한 마디로 생뚱맞은 congestion이 나올 수 있다.
예를 들어 혼잡도 데이터 적재 시스템이 3시간동안 특정 로케이션의 혼잡도만을 적재한다고 가정하자.
그러면 가장 최근순으로 나열했기 때문에 알맞게 매칭되지 않는다.
🙄 GROUP BY
congestion을 FK인 location_id로 그룹핑해봤다.
말 그대로 각 location_id별로 가져오라는거다.
그러나 group by를 쓰게 되니 또 다른 문제가 생겼다.
애초에 ORDER BY observed_at을 해야 하는데, group by를 location_id 하나로만 하니 불가능했다.
그래서 location_id, observed_at을 기준으로 하도록 바꿨다.
select count(*) from location;
select location_id, observed_at # group by 대상자가 아닌 컬럼을 가져올 수 없음
from congestion
group by location_id, observed_at
order by observed_at DESC
limit 9;
⚠ 문제 : GROUP BY의 성질상 다른 컬럼들을 가져올 수 없다.
내가 원하는건 congestion_level이었다.
✅ 해결
❗ 서브 쿼리
내가 깨달은 점은 3가지다.
- GROUP BY를 사용하면 AGGREGATE (MAX와 같은 통계 함수)가 가능하다.
- MAX(시간) 은 가장 최근의 시간이다.
- WHERE 절에는 2개 이상의 인자가 들어갈 수 있다.
아래는 SQL문의 흐름이다.
1. GROUP BY -> 각 로케이션의 가장 최근 혼잡도 레코드 하나씩만 가져온다.
2. GROUP BY를 썼으니 AGGREGATE가 가능하다. MAX(시간) 절을 사용하면 가장 최근 시간을 가져온다.
3. WHERE절에서 로케이션 id와 시간을 찾으면 된다!!
, location_id와 max(observed_at)만 가져온다.
→ WHERE IN 의 인자로써 넣어서 congestion과 location의 다른 모든 정보를 가져올 수 있도록 한다.
# 각 location별 최근 congestion 조회
select *
from congestion
where (location_id, observed_at) # 3. WHERE
in (select location_id, max(observed_at) # 2. 가장 최근 시간을 MAX로 가져옴
from congestion
group by location_id) # 1. GROUP BY 로케이션
order by location_id;
조금 더 생각해보니, 로케이션과 JOIN을 해서 한번에 가져올 수 있었다.
# JOIN까지
select c.congestion_id, c.congestion_level, c.location_id, l.name
from congestion as c
join location l on c.location_id = l.location_id
where (c.location_id, c.observed_at)
in (select c.location_id, max(c.observed_at) # 가장 최근
from congestion as c
group by c.location_id)
order by c.location_id;
QueryDSL로 구현 + Expressions.list()
QueryDSL에서 WHERE ( A, B ) IN (select A2, B2 from …) 부분을 구현하는 방법이 있었다.
Expressions.list()
이걸로 location.id 와 observedAt를 묶어서 복합키처럼 쓸 수 있었다.
“A 로케이션”의 “9시” 혼잡도 데이터 ⇒ UNIQUE한 한 레코드씩만 나오게 된다.
public JPAQuery<Location> getSingle() {// TODO
QCongestion subQCongestion = new QCongestion("subQCongestion"); // subquery 변수
return queryFactory.selectFrom(location)
.leftJoin(location.locationCategory, locationCategory).fetchJoin()
.leftJoin(location.congestionList, congestion).fetchJoin()
.leftJoin(location.locationBookmarkList, locationBookmark)
.where( // 각 location별 가장 최근 congestion 하나씩
Expressions.list(congestion.location.id, congestion.observedAt)
.in(JPAExpressions
.select(subQCongestion.location.id, subQCongestion.observedAt.max())
.from(subQCongestion)
.groupBy(subQCongestion.location.id))
);
}
이런 방법도! fetchJoin 최대한 많이 하기
location부터 가져오는게 아니라 congestion부터 가져오는 방법.
location 당 딱 한개씩만 (group by) 가져온다는 점에서 착안했다.
이렇게 하면 location이 congestion의 부모기 때문에 fetchJoin을 다 걸 수 있다.
public JPAQuery<Congestion> queryLocationFirst() {// TODO
QCongestion subQCongestion = new QCongestion("subQCongestion"); // subquery 변수
return queryFactory.selectFrom(congestion)
.where(Expressions.list(congestion.location.id, congestion.observedAt)// 각 location의 가장 최근 congestion
.in(JPAExpressions
.select(subQCongestion.location.id, subQCongestion.observedAt.max())
.from(subQCongestion)
.groupBy(subQCongestion.location.id))
)
.leftJoin(congestion.location, location).fetchJoin()
.leftJoin(location.locationCategory, locationCategory).fetchJoin()
.leftJoin(location.locationBookmarkList, locationBookmark).fetchJoin();
}
그러나 로케이션 서비스단에서 혼잡도를 메인으로 가져오는 쿼리는 그닥 좋지 않다고 생각해서 일단 기각했다.
chatGPT의 추천 : FROM절 서브쿼리
내가 짠게 정말 괜찮은 쿼리인지 의문이 들었다.
물어볼 곳도 없어서 chatGPT에게 물어봤다.
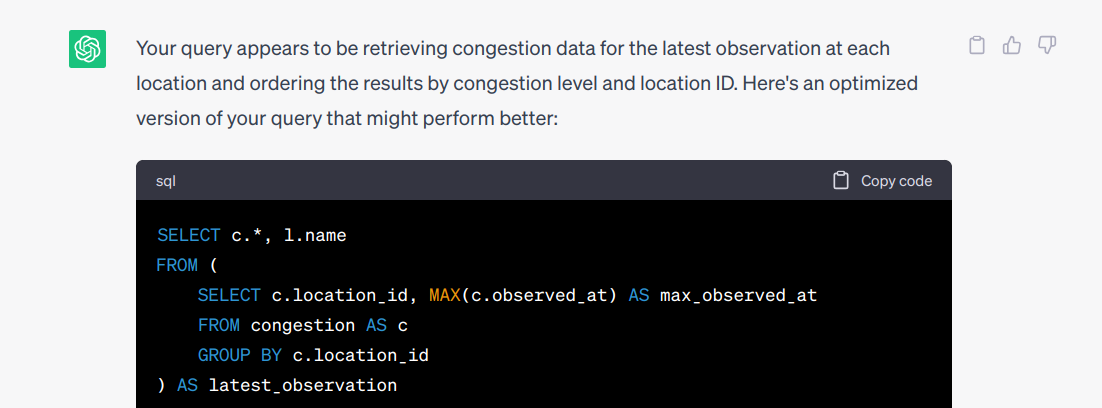
SELECT c.*, l.name
FROM (
SELECT c.location_id, MAX(c.observed_at) AS max_observed_at
FROM congestion AS c
GROUP BY c.location_id
) AS latest_observation
JOIN congestion AS c
ON latest_observation.location_id = c.location_id
AND latest_observation.max_observed_at = c.observed_at
JOIN location AS l
ON c.location_id = l.location_id
ORDER BY c.congestion_level, c.location_id;
" This approach can potentially be more efficient, especially when dealing with larger datasets, as it reduces the complexity of the join operation. "
잠재적으로 효율적일 수 있고(?), 조인 연산의 복잡도가 줄어든다고 한다.
솔깃했지만, QueryDSL에서는 FROM절 서브쿼리 (인라인 뷰)를 지원하지 않기 때문에 패스하기로 결정했다.
그러나 chatGPT의 답변중 인상적인게 있었는데, INDEX 설정이다.
congestoin 엔티티에 ('location_id', 'observed_at') 으로 복합 INDEX를 지정하면 쿼리문 최적화가 된다고 한다.
추후에 INDEX 리팩토링을 하면서 해봐야겠다.
'Back-end > Spring Boot' 카테고리의 다른 글
| [Spring Boot] @Valid 유효성 검사 (jakarta validation) (0) | 2023.08.27 |
|---|---|
| [Spring Boot] 연관관계 생성 메서드 삽질 (0) | 2023.08.23 |
| [Spring Boot] 스웨거 springdoc-openapi 적용 (webmvc-ui) (0) | 2023.08.09 |
| [Spring Boot] 예외처리 야무지게 하기 (0) | 2023.08.04 |
| [Spring Boot] 서비스에서 로그인된 유저 정보에 대한 의존성 최소화하기 (@AuthenticationPrincipal) + 스프링 계층 구조 지키기 (0) | 2023.07.30 |